
Earlier this week, MIT permanently pulled its 80 Million Tiny Images dataset — a popular image database used to train machine learning systems to identify people and objects in an environment. The reason? It used racist, misogynistic, and other offensive terms to label photos.
In a letter published Monday to MIT’s CSAIL website, Antonio Torralba, Rob Fergus, and Bill Freeman — the creators of 80 Million Tiny Images dataset — apologised and said they had decided to take the dataset offline and that it would not be re-uploaded. They noted that the dataset was too large, and the images were too small at 32×32 pixels to be inspected manually to guarantee that all offensive content be removed. They also urged that researchers refrain from using 80 Million Tiny Images in the future, and delete any copies that have been downloaded.
The problem was first reported by The Register, which says it alerted MIT of the findings of a paper identifying the issue. In the paper, authors Vinay Uday Prabhu and Abeba Birhane discovered that largescale image datasets like 80 Million Tiny Images were associating offensive labels with real pictures. Prabhu and Birhane found over 1,750 images labelled with the n-word, including the famous meme of a Black child who just loves colouring. According to the Register, the dataset labelled Black and Asian people with racist slurs, women holding children labelled as whores, and included pornographic images. Meanwhile, a graph in the paper illustrates there were thousands of photos labelled with derogatory terms like child molester, pedophile, rape suspect, and crude words for female genitalia.
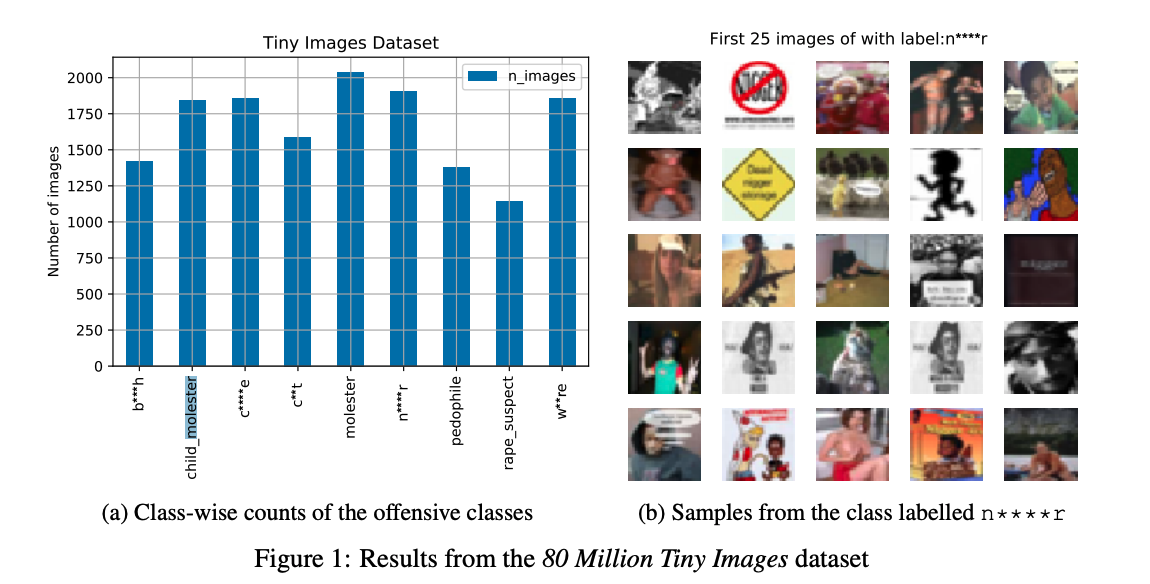
Part of the issue was how the dataset was built. 80 Million Tiny Images contains 79,302,017 images scraped from the internet in 2006 based on queries from WordNet, another database of English words used in computational linguistics and natural language processing. According to the creators, they directly copied over 53,000 nouns from WordNet, and then automatically downloaded images that corresponded to those nouns from various search engines. Except WordNet contains derogatory terms, and so you end up with results that inadvertently confirm and reinforce stereotypes and harmful biases.
“Biases, offensive and prejudicial images, and derogatory terminology alienates an important part of our community — precisely those that we are making efforts to include,” the creators wrote in their apology. “It also contributes to harmful biases in AI systems trained on such data. Additionally, the presence of such prejudicial images hurts efforts to foster a culture of inclusivity in the computer vision community. This is extremely unfortunate and runs counter to the values that we strive to uphold.”
80 Million Tiny Images is not the only large-scale vision database that Prabhu and Birhane took to task, however. Another problematic dataset is ImageNet. Last year, ImageNet removed 600,000 photos from its system after an art project called ImageNet Roulette illustrated systemic bias in the dataset. Unsurprisingly, ImageNet was also built based on WordNet. According to a Google Scholar search, 80 Million Tiny Images was cited in 1,780 studies. ImageNet returned even more results — roughly 84,700.
Biased datasets — even if unintentional — have far-reaching consequences when they’re used to train any type of artificial intelligence used in the real world. That’s especially true with regard to facial recognition tech. This week, Detroit Police Chief James Craig said that the facial recognition system used by his department didn’t work 95-97% of the time, following a case in which a Black man was wrongfully arrested after being identified by the department’s system.
Prabhu and Birbane also point out the primary flaw with huge datasets like ImageNet and 80 Million Tiny Images is that they scrape public photos without obtaining consent. For more ethically sourced sets, they suggest blurring faces, avoiding Creative Commons material, obtaining clear consent, and including audit cards, which allow curators to publish “goals, curation procedures, known shortcomings, and caveats” along with their datasets.