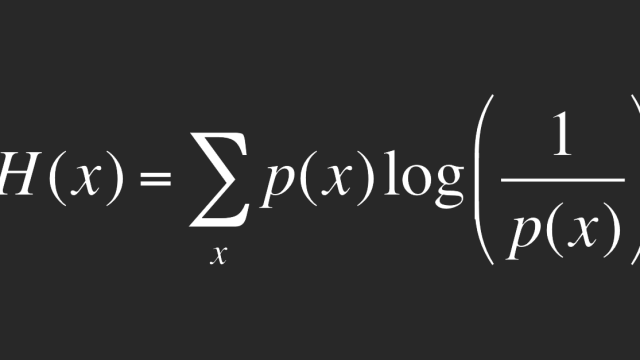
This is Shannon’s information theory, and it’s the equation that makes data compression possible. Without it, you couldn’t have loaded this page on the web.
Shannon’s equation codifies exactly how much information a string of numbers or characters actually contains. It allowed Shannon — and, later, software engineers — to develop new ways to compress messages without out losing any of their content.
The Bell Lab Years
Claude Shannon worked at Bell Labs in a post-war era when analogue was being slowly upstaged by digital. Analogue circuits had been used extensively in the 1930s to send messages, because it was easy enough to create simple electronics with off-the-shelf components that could create a sweeping range of outputs providing constantly varying signals containing information. But if you send a message made up of analogue signals down cables over long distances, things can go wrong. The signal weakens with distance and noise can creep into the signal, making it hard to tell one message from another.
Instead, digital systems were becoming the vogue. These systems, that we’re now all familiar with, used a simple on or off signal: 0 volts meant zero and another, higher voltage, meant one. String together enough ones and zeroes and you can represent numbers, letters, characters… whatever. And by setting the larger voltage high enough, weakening and degradation of the signal need never be a problem. (And even if it is, you can place a device at some point along the path to measure the signal and reproduce a new, clean digital signal without any noise — something you can’t do with an analogue system.)
Shannon was a keen digitalist. As a 21-year-old postgraduate student at MIT, he’d used digital mathematics known as Boolean algebra to help show that digital circuits could be used to construct complicated logical relationships. But as he sat at Bell Labs, in the twilight of his twenties, he began to wonder if the very essence of what was contained in those strings of ones and zeroes couldn’t be boiled down a little.
Bits and Pieces
Take a binary string of numbers that represents some kind of message — say, 00100001. It’s made up of a string of eight characters, each of which can either assume a value of 0 or 1. Those characters are known as binary digits, or bits and, naively, we might assume that each one of them represents a single piece of information: At each point along the string, we gain an extra understanding about whether a character takes the value of 1 or 0.
But Shannon’s simple yet stunning insight was to suggest that such an assumption was flawed. He realised that the presence of a 1 or 0 was only interesting if we don’t known what value each digit could take. Think of it as a coin toss. With a fair coin, every flip is interesting because you never know what you’re going to get; with a weighted one, every flip is boring because you always known what you’re going to get. Shannon’s observation was that information is related to the probability with which content of your message is expected to appear.
Probability Theory
Shannon’s theory of information, first published in the 1949 book The Mathematical Theory of Communication, which he co-wrote with Warren Weaver, explains this in algebraic form. The equation, at the top of the page, defines a quantity, H, which is known as Shannon’s entropy — essentially the amount of information contained in a given message.
The probability of a particular symbol — like a one or zero — occurring is written as p(x), where the x represents the one or the zero, or some other kind of symbol that’s being used. The equation then multiples the probability of a symbol occurring by the number of bits of information required to represent that particular symbol, which is given by the logarithm of 1/p(x). That makes intuitive sense: The information required is inversely proportional to probability, so that rarely occurring character provide more information. Finally, the equation adds up the information contribution for each value of x — which is what the big E-shaped symbol, actually an uppercase Greek sigma, does.
So imagine making our coin toss from from earlier a digital coin toss, where a head is a zero, tails is a 1, and they’re each equally likely. Substitute in those numbers into Shannon’s equation, and you find that a single digital coin toss provides 1 Shannon of information.
(Yep, he got it named after him. Actually, in technical circles people often just call 1 Shannon “1 bit” for short, but given we’ve already started talking about bits and that could get very confusing, we’ll stick with Shannons.)
Room for Improvement
What that means is that for a given bit of information or entire message you can work out exactly how much information is stored within it. If in the case of our digital coin toss we used a weighted digital coin, where the probability of getting a one is either 0 or 1, we may as well not bother sending the message at all: The receiver will always know what they’re going to get, so the message contains no information.
But if you think about longer chains of characters with different probabilities of ones and zeroes appearing, things get a little more interesting. Imagine a long chain of zeroes and ones: If each is equally likely to occur at any point along the string, there’s no better way to send the information than as it is. But if, say, zeroes occur 9 times out of 10 and ones just 1 time out of 10, then you can expect a lot more zeroes than ones. In turn the string has less information — and hence it has some redundancy. If we were clever, we could represent the long strings of zeroes we expect to see by some other, shorter description of the characters.
Shannon’s theory in fact explains that for any message there’s some redundancy given by the difference between number of characters, or bits, sent and the number of Shannons contained in the message, the number of bits of information it actually contains. And where there’s redundancy, there’s room for improvement.
Lossless Compression
If that seems slightly abstract — because, well, it is — let’s think about the English alphabet. Imagine we can only write in lowercase without punctuation, which gives us 26 letters and space to play with. Assuming the probability of each character occurring is equal — that is 1/27 — you can calculate the amount of information held within a character to be about 4.8 Shannons. But wait: an ‘x’ or ‘z’ isn’t as likely to appear in a sentences as an ‘r’ or ‘e’. So if you analyse the English language and work out the probabilities of each of the letters occurring and use those in Shannon’s equation instead, you end up with an information content in each character of just over 1 Shannon, and not much more even if you throw in capitals and punctuation.
Now, ASCII — the method typically used to encode text as ones and zeroes — represents each character in the alphabet, as well as punctuation marks and other such things, as an 8-bit code. So ‘a’ is ‘01100001’, ‘b’ is ‘01100010’ and so on. But, as we just saw, on average each character contains a little over 1 Shannon of information, meaning there’s large amount of redundancy built into the system which takes up capacity when we’re sending messages down phone lines, fibre optic cables or via 4G. There must be a simple code that we can use to remove some redundancy, where the most common characters are represented by shorter strings and the rarer ones are represented by longer strings.
In fact, using Shannon’s insight, that’s exactly what David Huffman realised while he was a PhD student at MIT in 1952. He developed a way of encoding messages based on the probability of characters actually appearing: The most frequent symbols are assigned the shortest codes and the less frequent symbols are assigned the longest codes. There are different implementations of Huffman’s technique, but typically an ‘e’ might be represented by a short code like ‘111’, while a ‘z’ would be represented by ‘1100010100’. Over the length of an entire sentence, where there are more e’s than z’s, that adds up. And, in theory, it means you can fit more information down a fibre optic cable or over a radio wave.
And you know what? It’s not just theoretical. A modified version of Huffman Coding was used to compress the black-and-white bitmap images that fax machine used to send down phone lines. An encoding format called PKZIP is based on Huffman’s work, and it’s used as the basis for .ZIP files. But the real kicker? Both MP3s and JPEGs both use an encoding package known as DEFLATE, based on Huffman coding, to squeeze the already compressed files down even further, so that they can zip through fibre or the air and to your computer or phone faster than would otherwise be possible. And for that, you can thank Shannon — for working out what really counted as information.