
Nearly one-third of drugs in development ultimately fail during clinical trials because the side effects are just too severe. Researchers at Cornell University have developed a promising new AI tool that better predicts which drug candidates are likely to be too toxic — and it’s based on the Oakland A’s winning strategy, immortalised in the blockbuster book and movie Moneyball.
Billy Beane (Brad Pitt), general manager of the Oakland A’s, challenged conventional wisdom about recruitment strategies in major league baseball. The pharmaceutical industry could benefit from a similar approach. (Image: Moneyball, 2011.)
They have dubbed it PrOCTOR (Predicting Odds of Clinical Trial Outcomes using Random-forest), and described their potentially game-changing approach in a new paper in Cell Chemical Biology.
“We’re trying to speed up the drug discovery process,” senior author Olivier Elemento of Cornell’s Weill Medical College said in a statement. “Many drugs look promising initially, then once they reach clinical trials they fail because they are toxic. We are trying to give researchers an early warning.”
By now, the statistical analysis the A’s employed to recruit players in the early 2000s is legendary, thanks in no small part to author Michael Lewis’s bestselling book. Lacking the big budgets of, say, the New York Yankees, they needed to find talented players other teams had overlooked and get them on the cheap.
The technical term for this statistical approach is sabermetrics (derived from the acronym for the Society for American Baseball Research). Its success has challenged long-held conventional wisdom about the criteria used to assess the value of individual players.
For instance, heavy hitters with high batting averages were overvalued, according to the sabermetric approach, while players with lots of walks (on-base percentage) were routinely undervalued. I’ll let Peter Brand (Jonah Hill’s fictional character in the movie) explain in more detail:
It’s essentially the same thinking economists typically employ when using statistics to identify undervalued stocks and bonds to give them an edge in their investments. And it helped the A’s reach the playoffs in 2002 and 2003. Similarly, the pharmaceutical industry might be relying on the wrong kinds of factors to predict a potential drug’s toxicity.
“People had feelings about certain factors being important in drug toxicity, and there wasn’t much science behind those judgment calls,” Elemento said. “We looked more broadly at drug molecule features that drug developers thought were unimportant in predicting drug safety in the past. Then we let the data speak for itself.”
First they crunched the numbers on the conventional rules (comparing a drug’s molecular structure) used by the industry to predict drug toxicity. Those results weren’t good. One predicted that fully 75 per cent of a sampling of drugs approved by the FDA would be too toxic to go into clinical trials. The second didn’t fare any better, predicting that 73 per cent of drugs that actually failed clinical trials would be safe.
Clearly something was off. So Elemento and his colleagues decided to develop their own tool, hoping to identify overlooked factors that could do a better job of making predictions about drug toxicity. They settled on a decision-tree machine learning approach that takes into account such factors as molecular weight and the various molecules in the body a particular drug is meant to target, among others.
Once PrOCTOR was operational, they “trained” the program by applying it to 784 drugs already approved by the FDA and 100 that had failed clinical trials because of high toxicity. And then they applied it to an even larger dataset of an additional 3236 drugs that had been approved in Europe and Japan.
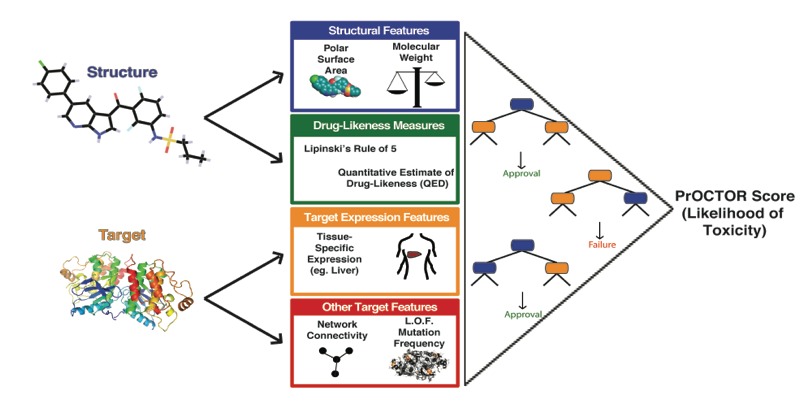
Schematic of the PrOCTOR approach. (Image: Olivier Elemento et al./Cell Chemical Biology)
The results: PrOCTOR did much, much better at predicting a drug’s toxicity than the conventional rules — including drugs that had been approved but were later found to have severe side effects. It wasn’t perfect. Some of those the program flagged for failure were for cancer treatments. Given the seriousness of the disease, there’s usually a higher bar for side effects for potentially life-saving drugs.
The program could make even better predictions with more data, according to first author Kaitlin Gayvert, perhaps even predicting the specific types of toxicity a given drug is likely to have. “For us, the more data the better,” she said.
Hopefully they won’t run into the problem that baseball teams now face, as more and more adopt the sabermetric approach, thereby eroding the edge originally gained by the Oakland A’s. That’s another useful rule of thumb to remember: you’re always scrambling to keep ahead of the curve.