
Walk into a roomful of people, and your first impression is just noise. Within seconds, you start to pick out words, phrases and fragments of conversations. Soon you’ll be merrily chatting with friends, oblivious to the din around you. But most of us never stop to think about exactly how our brain manages to pick out one conversational thread amid the noisy background in a crowded room.
It’s called the “cocktail party effect“. In a recent paper in PLOS Computational Biology, researchers at the University of Tokyo, led by Takuya Isomura, report that the secret lies in the brain’s remarkable ability to rapidly rewire itself — a property known as plasticity. Individual brain cells (neurons) can actually learn how to tune out many kinds of input and focus on one in particular, allowing us to have a meaningful conversation even in the middle of a noisy bar.
It’s well-known that the brain is constantly rewiring synapses in response to our experiences. But as Emilie Reas observed at PLOS Blogs Network, “Isomura and colleagues have shown for the first time that neurons can invoke these learning mechanisms to recognise and discriminate information.” This kind of work could one day be useful for improving speech recognition software — like Siri, who frankly kind of sucks at filtering out noise — acoustic sensing and maybe even hearing aids and cochlear implants.
The filtering process is much more complicated than merely detecting sounds, because the brain is also processing things like directionality, visual cues and temporal patterns of speech. For instance, a 2013 study used magnetoencephalography (MEG) imaging to measure whether visual cues, like facial expressions, can help us “predict” what we’re about to hear. The researchers found that subjects could follow a one-on-one conversation just fine, and struggled a bit more to stay focused in a cocktail party setting — as we all do. But they performed much better on the latter task if they had a face to go along with the speech patterns.
All that processing comes down to tons of electrical signals travelling throughout the vast network of neurons in the brain, so naturally neuroscientists are keen to learn more about the precise mechanisms by which this happens. Several years ago, Shihab Shamma of the University of Maryland, College Park, proposed that the cocktail party effect is the result of auditory nerve cells that are so adaptable, they can quickly “retune” themselves to focus on specific sounds. As I wrote back in 2011:
It’s kind of an auditory feedback loop that enables us to sort out confusing incoming acoustical stimuli. He’s surprised, however, by how quickly this process happens: auditory neurons in adult mammal brains make the adjustment in a few seconds. To Shamma, this suggests that the developed brain is even more “plastic” or adaptable than previously realised. We’re literally changing our minds.
Shamma has continued to study these kinds of changes in the brain. And another 2013 study provided strong support for his thesis by capturing that rapid adaptation in action with an implanted electrocorticography recording device. When we focus our attention on one person’s speech in a noisy room, that person’s voice will dominate the information processes in the brain.
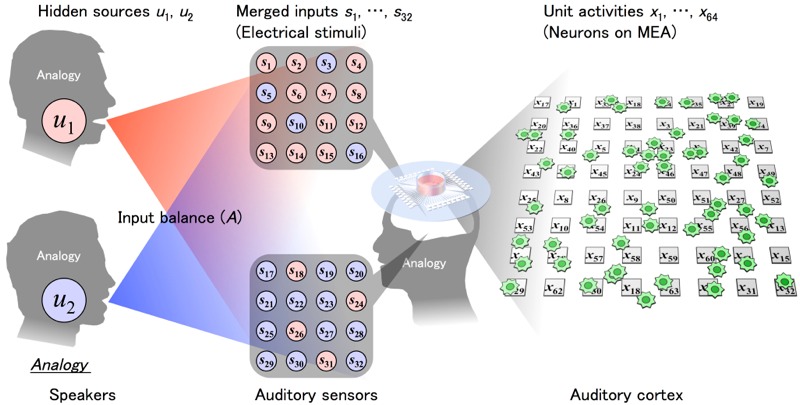
The latest Tokyo study provides more evidence of this remarkable plasticity. The researchers recorded the electrical activity in a dish of cultured rat neurons, then zapped the cells with electrical pulses in two specific patterns, with the goal of simulating the mix of voices one might encounter at a cocktail party. They did this over 100 times, varying the stimulus patterns, so they could track how the neurons changed their response to the stimulus.
Roughly half the neurons quickly “learned” to focus on one input pattern, while the other half learned to focus on the other pattern. This preference persisted as much as a day later, even in neurons that were only briefly exposed to the stimuli. The Tokyo team even pinpointed a possible mechanism: NMDA (N-methyl-D-aspartate) receptors in the brain, which are critical to the plasticity of the brain’s synapses as well as long-term memory formation. When they blocked those receptors, the cultured rat neurons showed almost no preference for one input pattern over the other.
Programming a computer to do what the brain accomplishes so easily has proven difficult. The cocktail party effect becomes the “cocktail party problem”. That’s because of the sheer number of possible sound combinations in speech.
Just the sound of one person’s voice is made up of many different frequencies that vary in intensity. Your typical speech recognition system, like Siri, works a little like autocorrect: it will break whatever you’re saying down into phonemes, the individual units that make up words. Those phonemes show up as specific patterns in acoustic spectrograms. The program then calculates the likelihood of one particular sound (“oh”) being followed by another (“en”). And just like autocorrect, speech recognition software often guesses wrong.
Better algorithms can help. In 2011, scientists at IBM’s T.J. Watson Research Center created an algorithm that could solve the cocktail party problem by focusing on the dominant speaker — whoever is speaking (or maybe shouting) the loudest. Just last April, scientists at the University of Surrey in the UK used a Deep Learning machine to separate human voices from the background in a wide range of songs. And last August, Duke University scientists successfully built a system capable of near-perfect accuracy (96.7 per cent) when tasked with distinguishing between three overlapping sound sources.
It’s still a much simpler task than filtering the myriad competing voices at your average cocktail party. But it’s a great start.
[PLOS Computational Biology via PLOS Blogs Network]
Images: (top) Gizmodo / (bottom) Isomura, R. et al. / PLOS Computational Biology