
A modern microprocessor is a tremendously complicated entity, and it has taken decades of work by thousands of people to get it where it is today. It’s nearly impossible to cover all the bases, but I’m going to try anyway. And get a bucket of popcorn ready — because this is going to be long.
Any modern system works on the basis of good abstractions, i.e. simpler modules on top of which more complex things are built. In my opinion, the modern processor can be broken down into the following very broad layers:
- Devices (transistors)
- Circuits
- Logic gates
- Simple logic blocks
- Processor
- Software
To begin with, let us start from a “middle ground,” one which is neither too complicated to understand nor too far from an actual processor: the logic gate. A logic gate will take some number of inputs, all of which are 0 or 1, and will output one bit which is again 0 or 1 according to some rule. For example, an AND gate will output 1 only if all its inputs are 1.
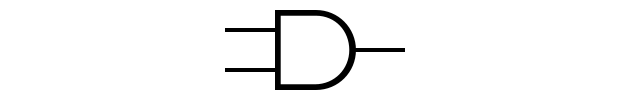
You might now start questioning me “But what do you mean by 0 and 1? What does that mean in terms of electricity?”. The answer is fantastically complicated. It can mean a level of voltage (0 is 0V, 1 is 1V), an electrical pulse (0 is no pulse, 1 is a pulse of 1V for 1 nanosecond, a billionth of a second), a photon (0 is no photon, 1 is 1000 photons), and so on, all depending on how the circuit was designed. This is the power of abstraction. You don’t need to know what the 0 and 1 meant in order to design things higher up (but you will make bad decisions higher up if you don’t know this, so the abstraction is obviously not perfect).
Now,do these very simple things actually let us do stuff? Let’s pretend that you’re about to start your own processor company, and you want to make a simple block that adds two numbers using these gates alone.
“But hold on,” you say, “What is a number in terms of 0 and 1? I only know numbers like 57 and 42, which are made of digits from 0-9, not only 0 and 1”. True, but see, 57 is only a representation of the number underneath, which is really 5*10+7. You can also represent 57 as 1*2^5+1*2^4+1*2^3+0*2^2+0*2^1+1*2^0. Voila! There you have it; 57 is the same as 111001 in this new system. You can convince yourself that any number can be represented in this form.
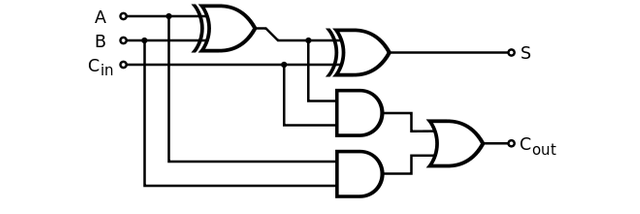
Now, let’s move on to the adder.. First of all, we’ll need to build a “half adder,” or one that takes in two bits and adds them, ultimately outputting two bits. So, if the two bits are both 0, it will output 00, if only one of them is 1, it will output 01, and if both are 1 it will output 10. Let us think one bit at a time and take the first bit first. After some time, we figure out “Oh! That bit is 1 only if both of the input bits are 1. So that we can get by an AND gate. Awesome!” Now we have half of our work done. Only one bit remaining.
Now we sit down to think again. Hmm, this other bit seems tougher. It is almost like an OR gate, but does not output 1 if both of the inputs are 1. Ok, let us not think about this more and just decide to call it a new type of gate, an Exclusive OR gate.

“Don’t worry,” I say, “we will hire some super awesome circuits engineers who can design such a gate in their sleep.” Now we draw an image of our amazing new circuit: a half adder.

But now you say, “We can add only 1 bit numbers. Our rival company can add numbers over 1 billion. How do we do that?” The answer is — surprise surprise — abstractions. You see, our current design can only add two one bit numbers, and the output is a sum and a “carry”, which now needs to be added to the next higher bit. This needs the addition of three bits, which our little guy can’t do.
So after another full day of wracking our heads over this, we figure out this will be a good circuit to do this and call it a “full” adder.
Now we have all the adding power of the world in our hands. You see, now we can just chain 32 of these little guys together like the following and we have in our hands a monster that can add numbers more than 1 billion, in the blink of an eye.
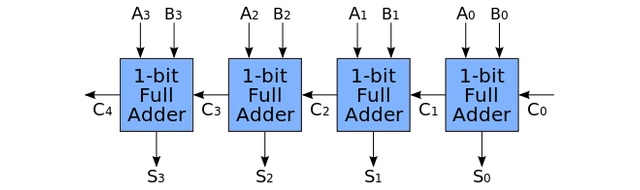
And here is the wonderful news: You can just go on making better and better gates, and your circuit will become better and better. That’s the power of abstraction.
Of course, as it turns out, our way of adding things is not really that great. You can do better — much better, in fact. But because of our friend abstraction, that can be done independent of the gates. If your newer circuit is two times better than the old one, and you have two times faster gates, you have a four times better circuit!
That’s one of the major contributors to how we got thousands of times better in a few decades. We built smaller, faster, less power consuming gates. And we figured out better and better ways of doing the same calculation. And after joining them together, it worked like magic!
We now slog for a year in our garage and build circuits that can multiply, add, subtract, divide, compare, and do all kinds of arithmetic, all within 1 nanosecond. We even make a tiny circuit which can “store” a value, (i.e. its output will depend on what value was written to it earlier). Let’s call it a flip-flop.
But, you see, one thing all our circuits have in common is that they just take in inputs and do the same operation over them to give the output. What if I wanted to multiply something, or another time, to add?
In this case, we need to not consider bits as just numbers. Let us try to represent the “actions” themselves in bits. Let us say 0 means “add”, 1 means “multiply”. Now, let us build a tiny circuit that sees a bit as a “command”, and selects between two inputs, I0 and I1, and outputs I0 if the command is 0, and I1 if it is 1. This is a multiplexer.
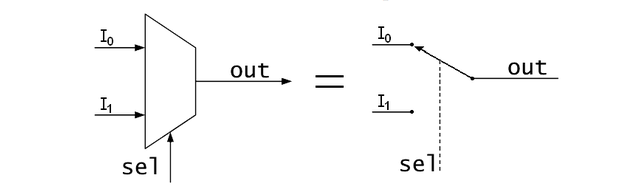
“Wow,” you say, “Now we just need a multiplexer to choose between the outputs of an adder and a multiplier, and we have got our solution! In fact, we can have lots of these multiplexers to choose between so many outputs — then we’ve got ourselves a truly amazing machine.
But wait — we have another idea. Remember those funny little flip-flops we built earlier? Well, what if we plug in a 1024-1 multiplexer at the output of 1024 flip-flops? Now we have what is called a 1 Kilobit memory. We can give it an “address,” and it will give us a bit back, which was the bit stored at that numbered location. What’s more, these bits can now be either “numbers” (data) or “commands” (instruction).
Here’s the really amazing thing: We have everything that we need to build a processor:
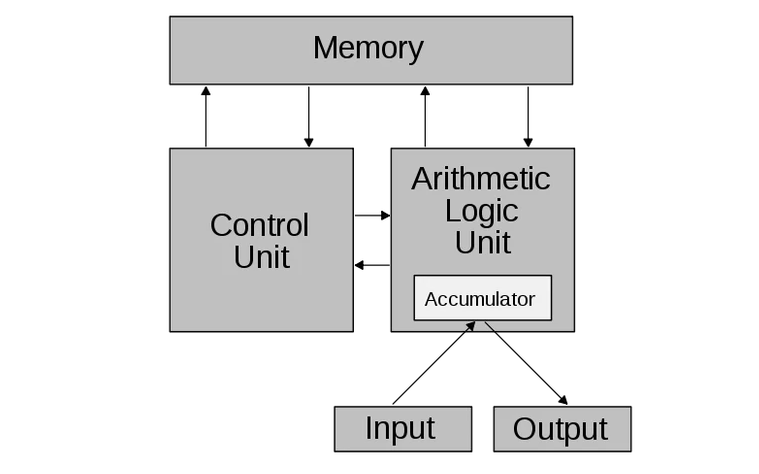
- First of all, we have a memory array MEM holding all the “commands” (instructions) and “numbers” (data).
- Second, we have a number called the “program counter,” one which we use to select which instruction to execute from MEM. It normally just increases by 1 in each step.
- Third, we have an arithmetic block with multiplexers.
- Fourth, we generate both the inputs to our arithmetic block from MEM.
- Finally, there are two types of instructions: data instructions and control instructions. Each data instruction contains four things: two addresses specifying which two numbers to pick from MEM, one command saying what operation to perform, and another location saying where to put the result back. The control instructions simply put another address back into the “program counter.”
This thing you’ve just built is called a Von-Neumann machine (yeah, crazy people like him figured all of this stuff out in 1945). Nowadays, people are beginning to question if this is the best way to build things, but this is the standard way any processor nowadays is built.
Well, when I said earlier that this is how all processors are built, I meant “theoretically,” and by “theoretically,” I mean “let us consider a cow is a sphere” theoretically. You see, your competitor’s CPU can run circles around your basic Von-Neumann CPU. You only have 1000 Kilobits of memory, your competitor can handle as many as billions (Gb) or trillions (Tb) of bits of memory. But now you say, no way in hell those guys can create a billion to one multiplexer and have its data within 1 nanosecond. True. Their secret sauce is something called locality.
What this means is that your program normally only uses a few locations of data and instruction memory at a time. So what you do is have a large memory consisting of GB’s of data, then you bring in a small part of it — the part that is being used currently, to a much smaller array (maybe 1 MB) called the cache. Of course, now you can have an even smaller cache below this cache, and so on, till you can get to something that you can read or write to in about the same amount of time you can do an arithmetic calculation.
Another powerful idea that you can do is called out-of-order processing. The concept behind this can be illustrated by the following program which computes X = (A+B)*(C+D).
- Add A and B and store it in U
- Add C and D and store it in V
- Multiply U and V and store it in X
In the normal way, you will just do it sequentially, going one instruction after another and finishing execution in 3 steps. But, if you have two adders in your system, you can run instructions 1 and 2 in parallel, and then be done in 2 steps. So you execute as much as possible every step and finish your execution faster.
Now, think back to the time when all you knew was a simple AND gate. This thing you built seems so alien from that. But it really is just layers upon layers of blocks, and reusing a simple block to build a more complex block. That’s the key idea here: A CPU is built only by patching together parts, which is built by patching together smaller parts. At the end though, if you just stare at the thing, it looks like this:
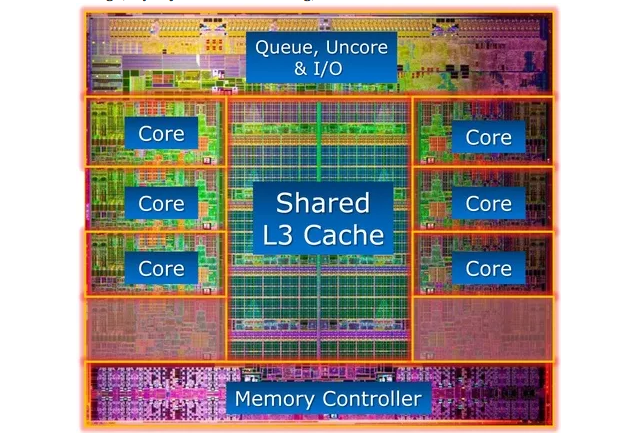
Of course, these are just the basics. What you say above is the equivalent ofresponding to “How does an F1 car work?” with “It has wheels, and a steering that guides the wheels, and an engine to run the wheels”. Truly, designing and building a CPU is one of the miracles of modern technology that involves a huge number of engineering disciplines (including e.g., quantum physics, metallurgy, photonics etc.). So now, let’s try to get into a bit more detail.
Fabrication
One of the amazing feats of technology has been the ability to create and connect billions of tiny transistors, each less than 100 nm (yes that’s nano, meaning one billionth of a meter) wide, into a precise pattern defined by the circuit designers and the CPU architects — and still make it impossibly cheap. It’s clear that creating and connecting such a huge number of transistors one by one is practically impossible by hand or, even by any form of mechanics, really.
To overcome that, we fabricate chips using a method called photolithography, and it’s the reason behind the extremely low price of processors compared to their complexity. The idea is similar to how an analogue photo used to be “developed” (if anyone remembers those). First I will describe how to create a pattern of silicon oxide on silicon (this is used in gates of transistors). First a layer of silicon oxide is deposited on the silicon. Then a layer of photoresist material is applied on top of it. This material is sensitive to light, but is resistant to “etching”. The inverse of the pattern to be created is also made in the form of a “mask” through which UV light is shone onto the photoresist. However, this then begs the question of how the mask was created in the first place.
Here is the magic of photolithography: the mask is actually much larger than the size of the pattern to be etched. The light shone through the mask is simply focused by a lens to be the right size when it falls on the silicon. Once the light changes the photoresist, it is etched away by a blast of plasma, leaving only the desired pattern on silicon oxide.

To create a layer of metal, on the other hand, a similar procedure is followed. However, now the inverse of the pattern is etched onto SiO2, and then metal is deposited on the “furrows” created by the SiO2.
The reason why this is so economical is because once you have the “mask”, you can create very large number of chips from it. Thus, although a mask is pretty expensive (few millions of $US), its cost is divided up into many chips, which makes each chip very cheap (pun not intended).
Types of Memories
As I said earlier, you can build a memory by connecting flip-flops to multiplexers. However, that is not an especially efficient way of doing things. One flip-flop consumes about 15-20 transistors. However, in practice there are two kinds of memory structures: static RAM (or SRAM in short), which uses 6 transistors per bit, and dynamic RAM (or DRAM in short), which uses only one transistor and one capacitor per bit. A static RAM is essentially two NOT gates connected in a loop like this.
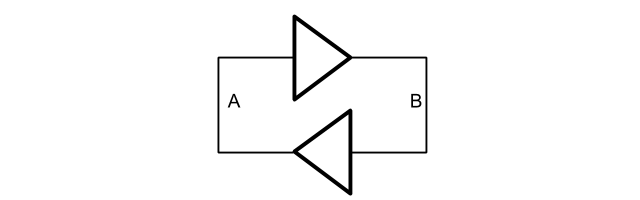
Clearly, there are two possible states for A and B, either A = 1, B = 0, or A = 0, B = 1. The idea is to apply some external voltage to push the loop into one state or the other, which is then the “stored” bit, and then simply read the voltage at A or B to “read” the bit.
On the other hand, dynamic RAM or DRAM, is even more simplistic and looks roughly like this.
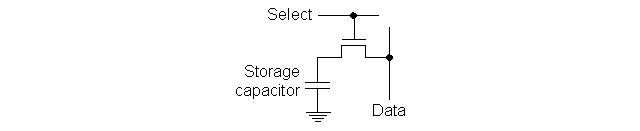
In this design, the transistor simply acts as a switch to store charge in the capacitor, in which case it is read as a 1, otherwise a 0. However, the charge in the capacitor leaks out of the transistor every so often. So it needs to be read and re-written at fixed intervals, and that’s why it is called dynamic RAM.
The caches in a chip are generally SRAM, since they are faster. However, the main memories in a computer are generally DRAM, since they are much smaller in size, and so a larger amount of memory can fit in a single chip.
Picture: Shutterstock/Volodymyr Krasyuk
How does a computer chip work? originally appeared on Quora. You can follow Quora on Twitter, Facebook and Google+.
This answer has been lightly edited for grammar and clarity.